Using Neural Networks to Detect Bots
Hi, in this blog post, I hope to explore the performance of neural networks, particularly auto-encoders, in detecting anomalous Dota 2 matches using the feature pipeline (if it can even be called such) I have published on my github. Essentially, the idea was to collect a bunch of matches from Patch 7.06c and then feed them into a neural network to detect weird matches.
To give a bit of a context, Dota 2 is an online video game designed and managed by Valve. In this game, five players are placed on two different factions, Radiant and Dire, for a total of ten players in a match. The goal of the game is clear objectives on the game map and make way to destroy the “throne” of the opposing faction. Each of the five players plays a different role on the team, so players are well differentiated, and teamwork is required. Basically, one has to acquire resources such as gold and magical items, eliminate the enemy multiple times, and do whatever it takes to clear the main objective of destroying the opposing throne.
The sort of data used for the project will be what I consider to be highly representative bits of information from Dota 2 matches. Normally, some features would be categorical (such as the type of hero a player is selecting) or numerical (such as the gold spent by a player), and the categorical features would need to be encoded into some sparse representation. This was the case in earlier attempts when I used the character, or hero, chosen by each player and the items they bought. Unfortunately, these categorical features had high cardinalities, and I ended up only using the numerical features such as the kills per minute or gold per minute of the different players— while also making sure to differentiate by role and faction. A more complete list of the features used would include:
- kills, gold, and experience per minute
- total gold, kills, assists, and deaths and differentiated by player as well
- hero damage and healing
- tower kills and courier kills by player
- game duration
- abandons
- negative and positive votes
- ward usage
The network architecture consists of a single hidden layer with sigmoid activation function and the output layer using the identity activation function, but more complicated networks might have multiple layers of weights as the encoder and decoder.
The matches in the designated training and test sets would be used train the neural network and subsequently generate a distribution of reconstruction errors. If the auto-encoder and the features used were both perfect, then the matches would be reconstructed perfectly with no errors; in actuality, some the features of some matches will be reconstructed with higher errors than others.
The idea is that an auto-encoder can find a sparse representation to encode most matches, and the matches with higher reconstruction errors could be considered anomalous. Other uses of auto-encoders include dimension reduction or de-noising, but I will go along with the anomalous interpretation. Ideally, the most anomalous matches will have situations where some of the players feed or troll or bots are present in the game.
The behavior, training, and tuning of auto-encoders is very similar to that of regular (not necessarily regularized) multi-layer perceptrons. Feed-forward and backpropagation are still key parts of the algorithm. The main constraint is that the final output layer needs to match the input layer as much as possible.
To gather data, I used the OPENDOTA API over a period a little over a week to gather about 170,000 matches. The data gathered included things such as what heroes went to which lane, the kills per minute of the Position 1 player from Radiant (and Dire), ward uses, and various other things that could be relevant in a match. I selected for All Pick or Captain’s Mode Public and Ranked matches. Since the game is mostly balanced for these sorts of games, then I figured the auto-encoder would have an easier time training on this sort of data.
After generating the data, I did standard feature scaling to make the numerical data for susceptible to learning. I replaced missing values with zeros, as a missing value for the ancient creep kills for the position 5 player on a team indicated that the player just did not harvest ancient creeps. At this point, I also selected out some of the data I gathered because it data quality issues or because it confused the network model in reaching my purpose.
The data goes into a TensorFlow implementation of a simple auto-encoder model. The model has one hidden layer with three quarters of the number of neurons of the input layer (and output layer). I used the AdamOptimizer to train the network. Stochastic gradient descent was having difficulties with local minima. After training, I calculate the reconstruction error for each match, and the reconstruction error is simply only the sum of the square of the residual across all the features.
x = tf.placeholder(tf.float32, [None, NumFeatures])
y = x
weights_1 = tf.Variable(tf.random_normal([NumFeatures, layer_size[0]], stddev = 1.0/NumFeatures/100), name='weights_1')
bias_1 = tf.Variable(tf.random_normal([layer_size[0]], stddev = 1.0/NumFeatures/100), name='bias_1')
weights_2 = tf.Variable(tf.random_normal([layer_size[0], layer_size[1]], stddev = 1.0/NumFeatures/100), name='weights_2')
bias_2 = tf.Variable(tf.random_normal([layer_size[1]], stddev = 1.0/NumFeatures/100), name='bias_2')
layer1 = tf.tanh(tf.matmul(x, weights_1) + bias_1)
output = tf.tanh(tf.matmul(layer1, weights_2) + bias_2)
cost = tf.reduce_mean(tf.reduce_sum(tf.pow(y-output, 2), 1))
rank = tf.rank(cost)
learning_rate = 0.000001
beta1 = 0.5
beta2 = 0.5
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate, beta1=beta1, beta2=beta2)
gradients, variables = zip(*optimizer.compute_gradients(cost))
gradients, _ = tf.clip_by_global_norm(gradients, 5.0)
train_op = optimizer.apply_gradients(zip(gradients, variables))
variable_dict = {'weights_1': weights_1, 'weights_2': weights_2,
'bias_1': bias_1, 'bias_2': bias_2}
saver = tf.train.Saver(variable_dict)
init = tf.global_variables_initializer()
ckpoint_dir = os.path.join(os.getcwd(), 'model-backups/model.ckpt')
Afterwards, the anomalous matches are the matches with a total reconstruction cost at the 99th percentile or higher. This level was determined by manual inspection at the 90th, 95th, 98th and 99.9th percentiles.
I realize that there are many false positives in the anomalous matches. I think simple filtering rules and further improvements to the model mitigate the real risk of these concerns. In order to detect leavers by using anomalous matches, one could filter matches where an abandon happened given certain game durations and first blood timers. A particularly useful filter for detecting feeders is the following: In matches with a total residual being in the 99th percentile, if the feature with the highest reconstruction error was related to player kills (such as kills per minute or total deaths), then the match quite often included feeders or bots. This is not to say that matches in this higher end of the spectrum of total residuals did not include feeders or bots when most deformed feature was something unrelated to player kills, but false negatives are less costly than false positives.
Some results are pretty indicative of partial success. The follow matches had high enough residuals to count as anomalous matches and are clearly bots (or really dedicated players):
- https://www.dotabuff.com/matches/3215153289
- https://www.dotabuff.com/matches/3215384305
- https://www.dotabuff.com/matches/3215254006
- https://www.dotabuff.com/matches/3215350255
Some matches are just really weird:
- https://www.dotabuff.com/matches/3215162338
- https://www.dotabuff.com/matches/3215344415 (In this particular match, Disruptor placed more wards than expected, and a player abandoned.)
I am not really sure what is going with these matches:
Following the idea of success, using some of these bot matches, I was, incidentally, able to find some players that seemed to be losing a large amount of games via bots in order to play Battle Cup games at skill levels lower than their typical tier level. Since I happened onto these accounts by accident, I think further focus could serve the purpose of finding players that tend to exploit the matchmaking rating (MMR) system. Although, this is limited to players exposing their player data to third-parties.
Unfortunately, I had some issues with the data that were not foreseen later, and there is nothing beyond a rudimentary design in the neural network, nonetheless, I found what are some interesting trends that corresponded to some of my prior intuitions, and, more excitingly, some trends completely contradicted my expectations. Because of this, I’d say that some more effort into one of the tasks I mention above could enable the data (or a similar batch) into a more directed effort such.
These data quality issues did impact the distribution of the residuals in initial iterations. In fact, the first few times I tried this experiment, I was getting matches from the arcade mode Dark Moon.
Not all the matches I recorded are now available on Dotabuff.
A somewhat nuanced issue is the large number of matches were a substantial number of the players do not give third parties their match data. In these games, a substantial number of players would not have some features accessible such as actions per minute, so I stopped collecting that feature in later iterations of this pipeline/model.
Other issues in data arise from me collecting the wrong features or missing some features that could have been useful. The training and test data has which heroes were selected for the particular roles—along with their items—but the high cardinality of these dimensions made training infeasible on the machine I was using and the limits of my patience.
I also messed up in encoding the positive and negative votes that a match has. In fact, the match with the highest residual also had among the highest of negative votes. One should be suspect if a match has a residual when it comes to the number of votes, at least for this batch of data. When graphing, I excluded matches with these data abnormalities to better show behavior.
Often times, my intuition about certain features was just wrong. In a first few of the iterations, matches were sometimes considered anomalous if one of the players pinged a lot. Often times my intuition was right. Sometimes a match would be considered highly anomalous because a player spent an abnormal amount of gold for his role. Often times, this would be a player spam buying wards or teleport scrolls such as in match 3215353856 (Dire Position 2 spent an abnormal amount of gold relative to his performance).
I removed neutral kills as a feature at some point because they were dominating the effect of detecting outliers in lower priority positions, but I retained ancients because ancients still had signal towards anomalies (such as games with 5 carries). I also do not consider rune pickups or pings anymore.
In the iteration of the project at the time of writing this article, there is some interesting behavior on-going with wards. I expected that sentry and observer ward usage would be highly indicative of anomalous matches where players get frustrated and spam buy sentries. Often times, these matches actually corresponded to a player just buying more wards than usual but with good intentions such as in this match https://www.dotabuff.com/matches/3215448302.
Here are some generated graphs that attempt to demonstrate the effect of some of the features (or their combinations) on the residual. Surprisingly, the overall trends when looking at some of the individual features are the opposite of what one might expect in high residual games. There is only a weak correlation, if any, in most of these graphs, which highlights how contextual DotA matches are; any particular feature is meaningless without other metrics because of how tightly correlated everything is.
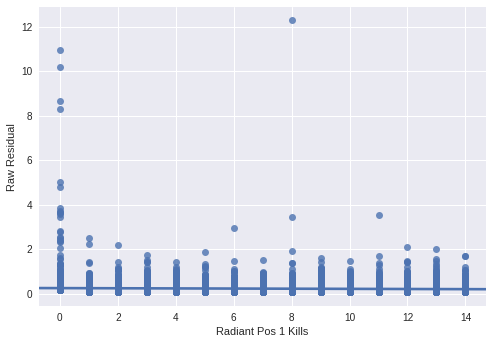
You can see that the Position 1 player on the Radiant side tended to have no activity in high residual matches.
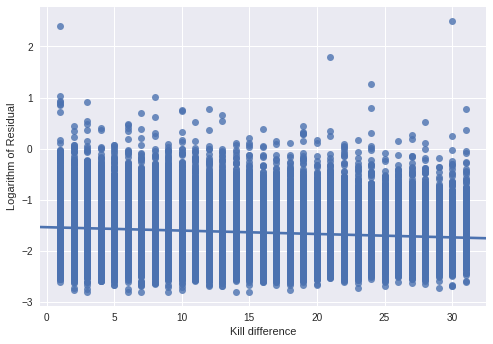
The logarithm of the absolute total kill difference between teams against the residual. There is a downward trend, suggesting that most anomalous games have little action.
Below is a sample table of games in the 99th percentile of reconstruction error that correspond to the filtering. The possible identification of feeders and bots using the appropriate filters is pretty consistent. If you want to dive at the data yourself, feel free to access the Github repository for this project. If you want access to all the data, feel free to message.
| actual | column | match id | predicted |
|---|---|---|---|
| 49.0 | negative votes | 3215497967 | 1.0 |
| 15.0 | negative votes | 3215097220 | 1.0 |
| 9.0 | negative votes | 3215312675 | 1.0 |
| 0.997236430645 | dire pos5 courier kills | 3215162338 | 0.254108220339 |
| 0.967831552029 | radiant pos3 gpm | 3215181105 | 0.215277791023 |
| 0.986187636852 | dire pos5 kda | 3215377994 | 0.675353765488 |
| 7.0 | negative votes | 3215271631 | 1.0 |
| 0.915403366089 | dire pos4 gpm | 3215289100 | 0.162800624967 |
| 0.915403366089 | dire pos4 gpm | 3215279863 | 0.155206382275 |
| 5.0 | negative votes | 3215253055 | 1.0 |
| 0.977942168713 | radiant pos1 sentry uses | 3215448302 | 0.730815529823 |
| 0.0236208867282 | dire pos3 gpm | 3215416370 | 0.595808267593 |
| 0.243853777647 | radiant pos3 gpm | 3215261563 | 0.536930799484 |
| 4.0 | negative votes | 3215294948 | 0.999999940395 |
| 0.996014475822 | radiant pos5 kills | 3215155134 | 0.729707717896 |
| 0.172037020326 | radiant pos4 gpm | 3215350255 | 0.478152662516 |
| 0.765351176262 | radiant pos1 kpm | 3215341221 | 0.473023504019 |
| 0.796920537949 | radiant pos2 gpm | 3215306187 | 0.594073414803 |
| 0.995038449764 | dire pos4 gpm | 3215302636 | 0.616404891014 |
| 0.995248615742 | dire pos5 gpm | 3215316820 | 0.661065816879 |
| 0.991396725178 | dire pos3 sentry uses | 3215190109 | 0.725191056728 |
| 0.994378209114 | dire pos2 gpm | 3215355847 | 0.634865164757 |
| 0.992697298527 | radiant pos3 kills | 3215130854 | 0.734208106995 |
| 0.99599146843 | radiant pos1 kills | 3215259897 | 0.731749773026 |
| 0.420948237181 | dire pos1 totalgold | 3215394671 | 0.15580162406 |
| 0.853668451309 | dire pos4 deaths | 3215152225 | 0.677466273308 |
| 0.97054040432 | radiant pos2 kpm | 3215274711 | 0.548053383827 |
| 0.417959868908 | dire pos3 xpm | 3215366609 | 0.140711635351 |
| 0.837321698666 | radiant pos2 courier kills | 3215449992 | 0.687711238861 |
| 0.417725324631 | radiant pos2 xpm | 3215376405 | 0.142942205071 |
| 0.617924034595 | dire pos5 kpm | 3215268540 | 0.222700610757 |
| 0.772488415241 | radiant pos4 kpm | 3215420902 | 0.579163551331 |
| 0.720203399658 | dire pos1 hero heal | 3215332931 | 0.546277999878 |
| 0.720203399658 | dire pos1 hero heal | 3215327547 | 0.547204256058 |
| 0.570976436138 | dire pos5 kpm | 3215354992 | 0.277706980705 |
| 0.696351587772 | dire pos2 lasthits | 3215254939 | 0.59213912487 |
| 0.896779537201 | dire pos5 tower kills | 3215149372 | 0.706301689148 |
| 0.846275269985 | radiant pos1 observer uses | 3215370025 | 0.688222169876 |
| 0.99476057291 | dire pos2 sentry uses | 3215201012 | 0.0275219380856 |
| 0.737460970879 | dire pos3 totalxp | 3215272070 | 0.62419462204 |
| 2.0 | negative votes | 3215223639 | 0.999818563461 |
| 0.702699840069 | dire pos1 hero dmg | 3215422492 | 0.599272608757 |
| 0.420081436634 | radiant pos1 xpm | 3215260456 | 0.113636702299 |
| 0.13533718884 | radiant pos3 sentry uses | 3215354934 | 0.0243814960122 |
| 2.0 | negative votes | 3215377592 | 0.999819636345 |
| 2.0 | negative votes | 3215445972 | 0.999818325043 |
| 0.992697298527 | radiant pos3 kills | 3215101148 | 0.748484134674 |
| 0.776657044888 | radiant pos4 sentry uses | 3215174827 | 0.654739558697 |
There is still a lot of work to attempt in the architecture of the auto-encoder.
I attempted ReLu activation functions, but I was having
issues with dying neurons, especially in the iterations when I had multiple hidden layers.
The hyperparameters have yet to be explored.
To introduce regularization, one could attempt to modify the objective function or introduce dropout.
Nonetheless, hopefully this suggests a path to automate the moderation of the player community in order to have higher quality games.